A Visual Guide to Gemma 4 12B
发表时间: 2026-06 · Blog post by Maarten Grootendorst (newsletter.maartengrootendorst.com)
文章标题: A Visual Guide to Gemma 4 12B
作者/机构: Maarten Grootendorst / Google DeepMind
A1 主要贡献
本文介绍了一款新发布的模型 Gemma 4 12B,旨在填补 E4B 和 26B A4B 模型之间的空白。该模型的核心创新在于其“无编码器(encoder-free)”设计。传统的多模态模型通常依赖独立的、基于注意力机制的编码器(如视觉编码器和音频编码器)来处理图像和音频输入,然后将处理后的嵌入(embeddings)传递给大语言模型(LLM)。Gemma 4 12B 则移除了这些专用的编码器,将所有模态的处理统一在 LLM 内部。
研究目标与创新点:
1. 统一多模态处理:通过移除专用的视觉和音频编码器,将理解多模态输入的负担直接交由 LLM 本身,从而实现一个统一的、无编码器的多模态架构。
2. 降低推理延迟:传统模型中,LLM 必须等待编码器完成对图像或音频输入的处理。无编码器设计使得 LLM 可以更早地开始处理输入并生成输出,从而减少了整体的推理延迟。
3. 简化模型结构与参数:移除了庞大的编码器(例如,视觉编码器可达5.5亿参数),代之以轻量级的嵌入模块(约3500万参数),显著减少了模型总参数量和架构复杂性。
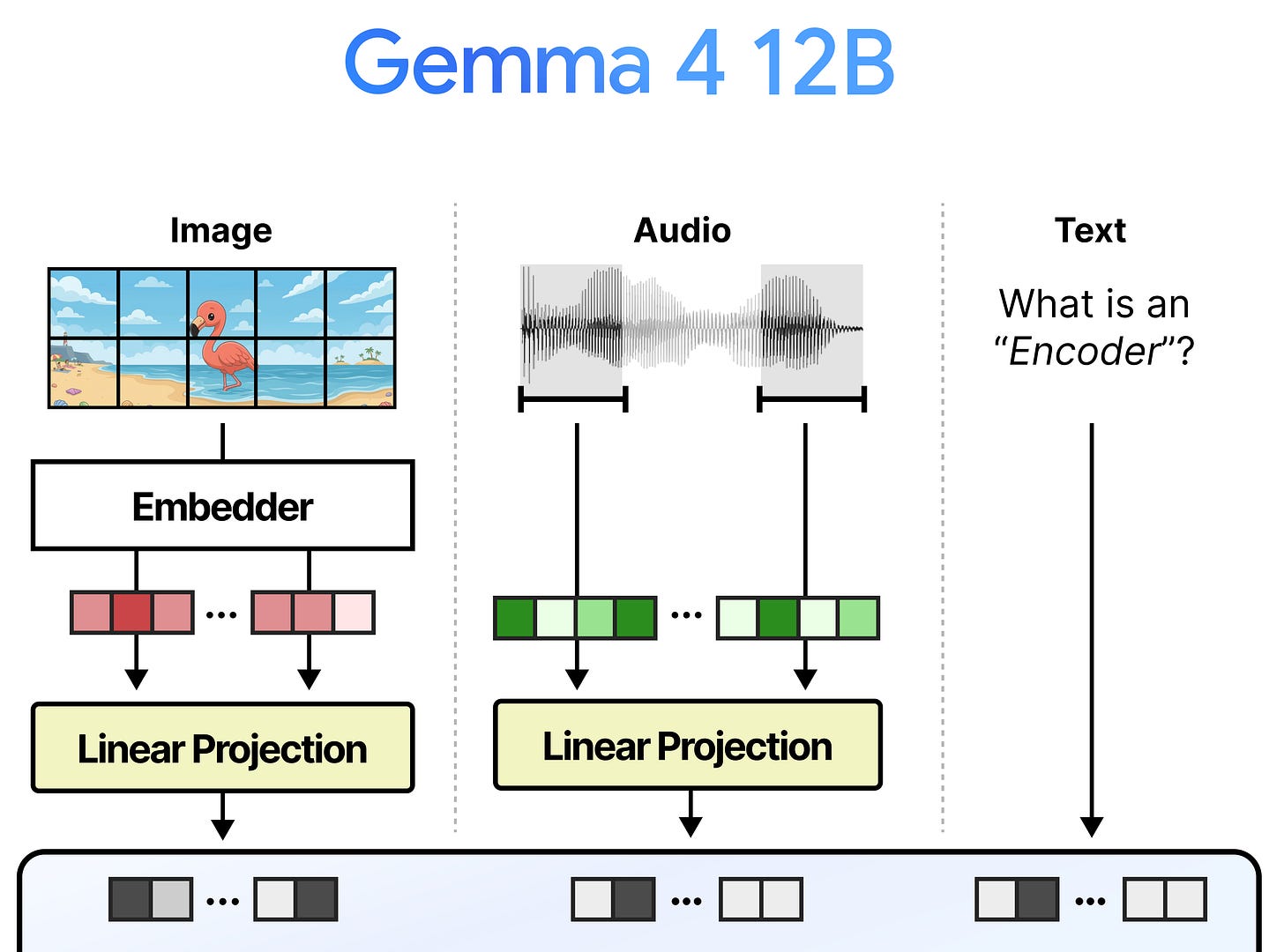
本文详细阐述了移除视觉和音频编码器并用更快速的替代方案取而代之的技术细节,展示了这款 12B 模型如何在不需要编码器的情况下处理音频和图像输入。
A3 背景知识
多模态输入的编码与连接
LLM处理文本的方式。当文本被输入到LLM时,模型自身的词元嵌入层(token embedding layer)负责将其分割成词元(tokens)并转换为嵌入(embeddings)。这些嵌入随后被传递到LLM的解码器层,解码器层中的注意力机制用于创建这些词元嵌入的有意义的、上下文相关的表示。
传统多模态处理流程。为了让LLM能够理解文本以外的模态(如音频和视觉),大部分处理工作通常不由LLM直接处理。取而代之的是,一个独立的、由注意力机制驱动的编码器(encoder)被用来首先将输入处理成嵌入。这种编码器本身通常是一个小型的Transformer模型,它像LLM一样使用注意力机制来处理输入。
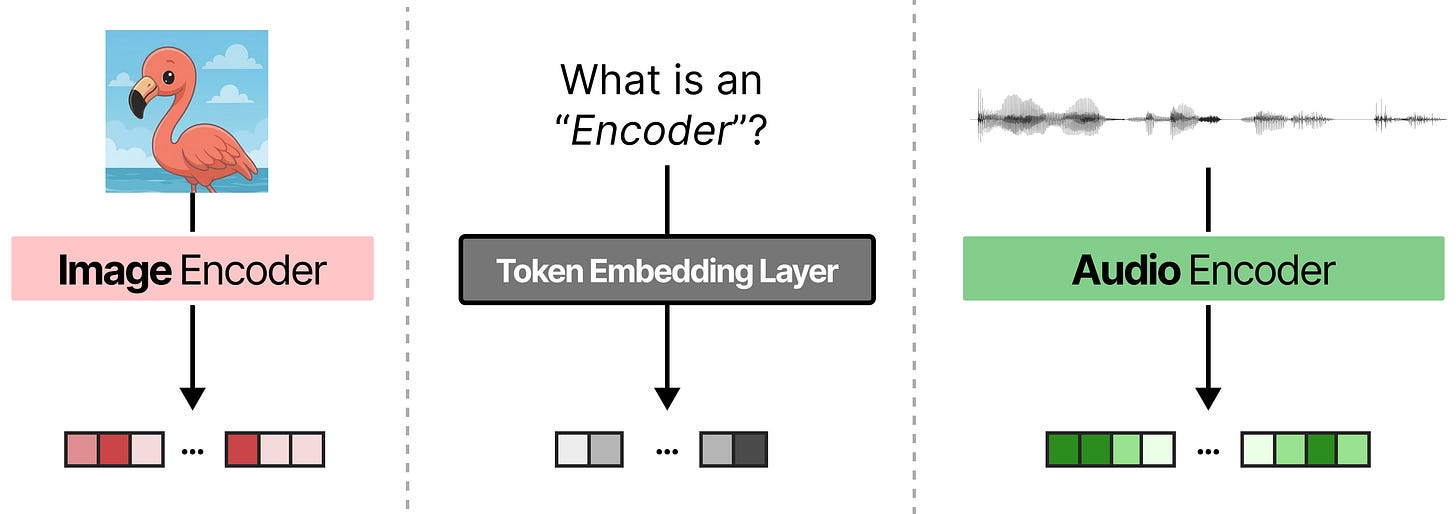
连接器的作用。然而,编码器产生的嵌入不能直接被LLM使用。它们的维度通常不同,并且在n维空间中的行为可能有所差异。一种常见的技术是使用所谓的“连接器”(connector)。连接器将编码器的输出转换为与LLM词元嵌入相同的维度。毕竟,大型语言模型主要是在文本上训练的。
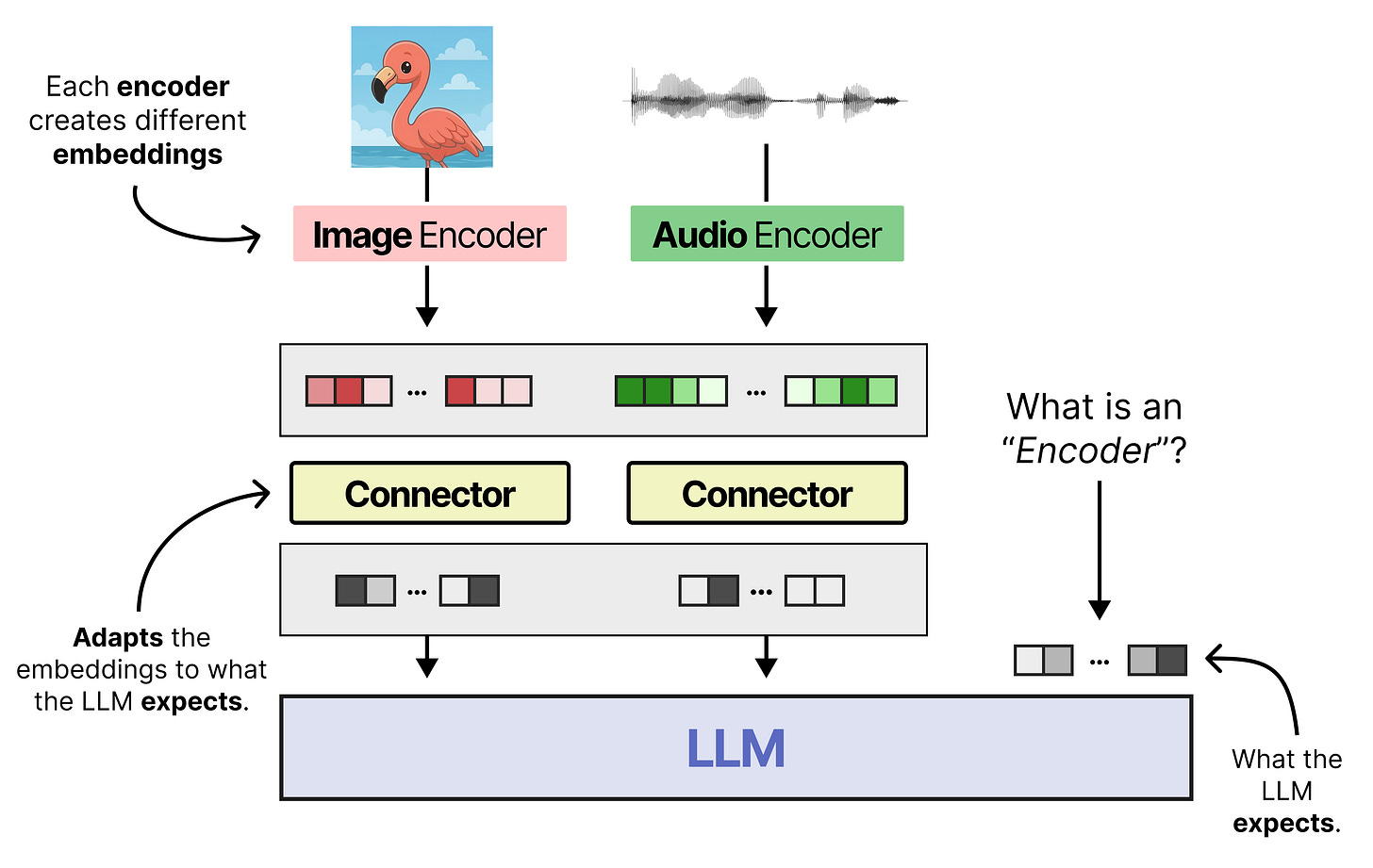
传统方法的局限性。这两个组件(编码器和连接器)通常用于使LLM具备多模态能力,并且效果很好,被许多开源多模态LLM(如Gemma 4和Qwen 3.5)所采用。但这并非没有代价。非文本编码器需要先处理其输入,然后LLM才能开始工作,这增加了模型的推理延迟。此外,由于编码器本身(在绝对意义上)相当大,这也增加了大量的参数。因此,一个自然而然的问题是:我们是否可以不需要编码器,而仅仅依靠连接器就足够了?
A2 方法细节
Gemma 4 的多模态能力(传统方法)
Gemma 4 支持三种模态:文本输入(所有模型)、图像输入(所有模型)和音频输入(仅限E2B和E4B模型)。所有这些模态都需要一个类似Transformer并带有注意力机制的架构来处理输入。对于图像和音频输入,使用了两个独立的Transformer编码器来创建LLM可以使用的视觉和音频词元。
视觉编码器
编码器规格。Gemma 4 E2B、E4B、26B A4B和31B模型都带有一个用于处理输入图像的视觉编码器。这些视觉编码器具有相当大的参数量:E2B和E4B模型的编码器有1.5亿参数,而26B A4B和31B模型的编码器有5.5亿参数。
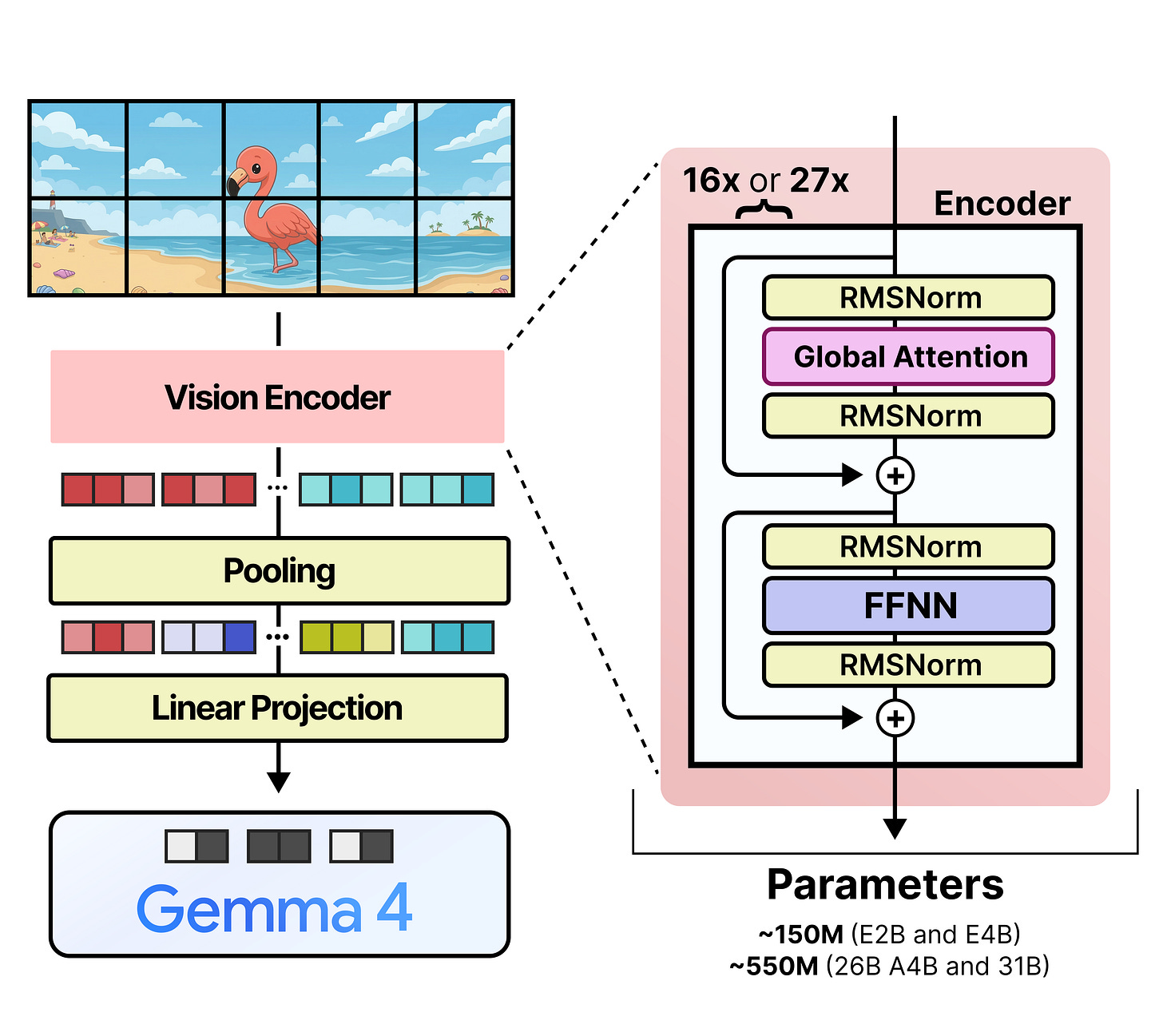
处理流程。输入图像的图块(patches)大小为16x16像素。经过视觉编码器处理后,它们被汇合成一个3x3的图块网格。
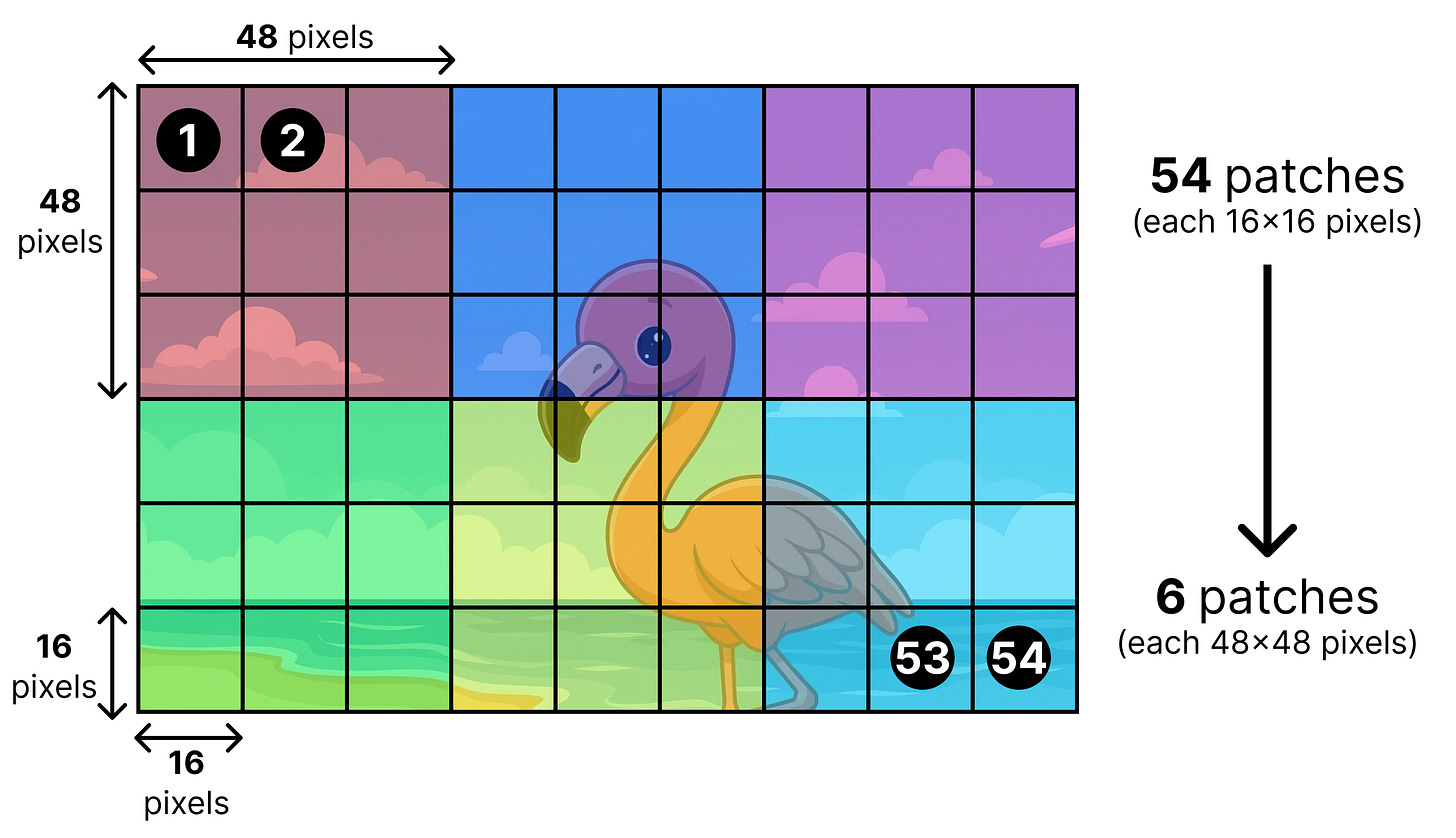
连接与嵌入。这些汇合后的图块嵌入代表了48x48像素的区域。在汇合步骤之后,一个小型线性投影层(即连接器)被用来将图块嵌入转换为适合LLM处理的嵌入。这样,最终的图块嵌入与词元嵌入具有相同的形状,并与词元嵌入交错排列。
音频编码器
编码器规格。较小的Gemma 4模型(E2B和E4B)也带有一个用于处理输入音频的音频编码器。与视觉编码器一样,这些音频编码器也有一定的参数量。E2B和E4B的音频编码器是相同的,都有3.05亿参数。
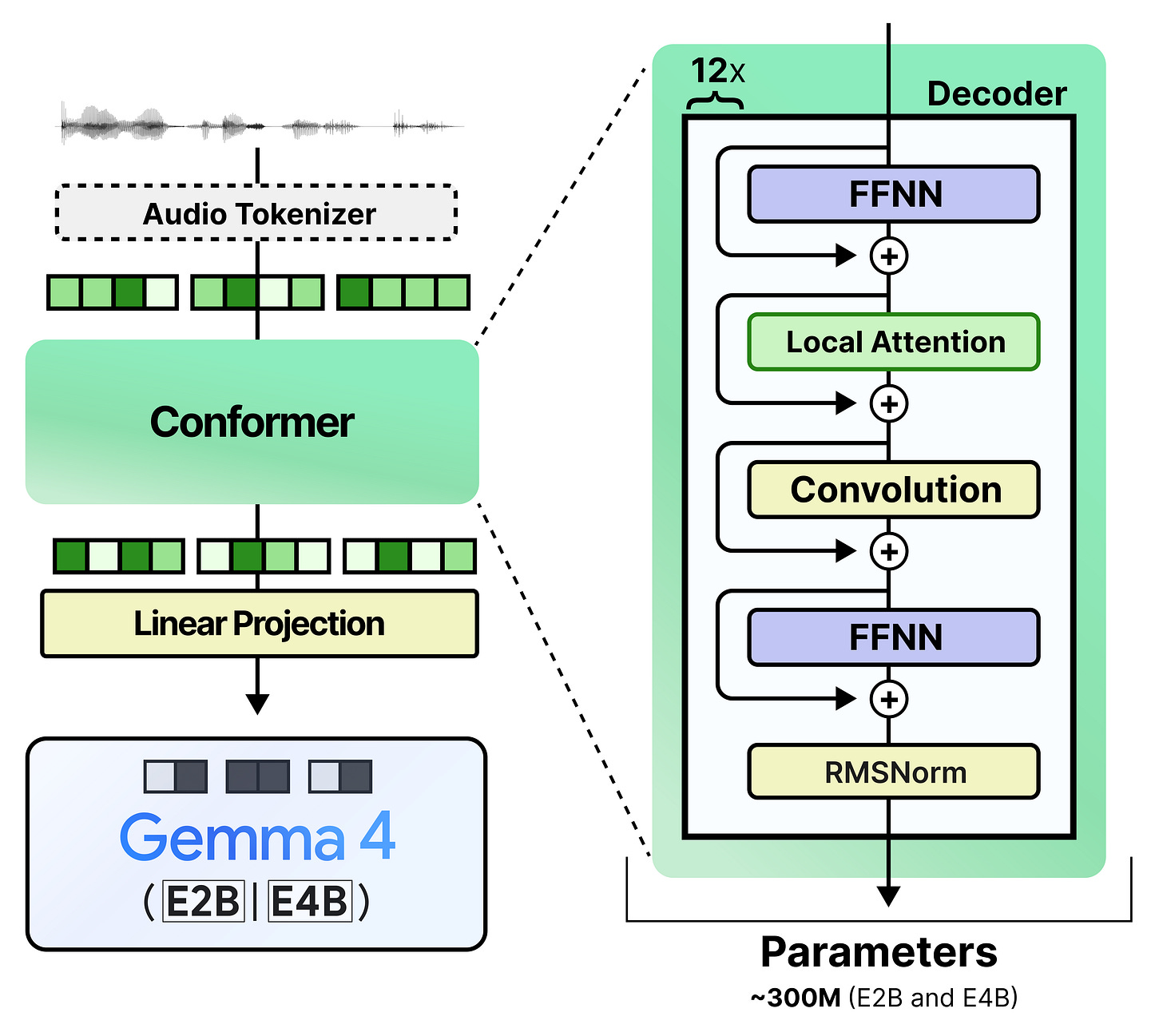
连接与嵌入。与视觉编码器类似,音频编码器在处理完音频输入后,将其嵌入投影到与词元嵌入相同的维度空间中。由此产生的音频词元嵌入与文本词元嵌入交错排列。这些编码器虽然与其对应的Gemma 4模型相比相对较小,但仍然需要处理输入,这会增加延迟并使整个流程变得复杂。此外,在微调Gemma 4模型时,通常只微调LLM本身,而不微调其编码器,这使得编码器难以与模型同步增长。
使 Gemma 4 12B 实现无编码器
为了移除编码器并向社区提供一个新模型,Google DeepMind 推出了 Gemma 4 12B 模型。
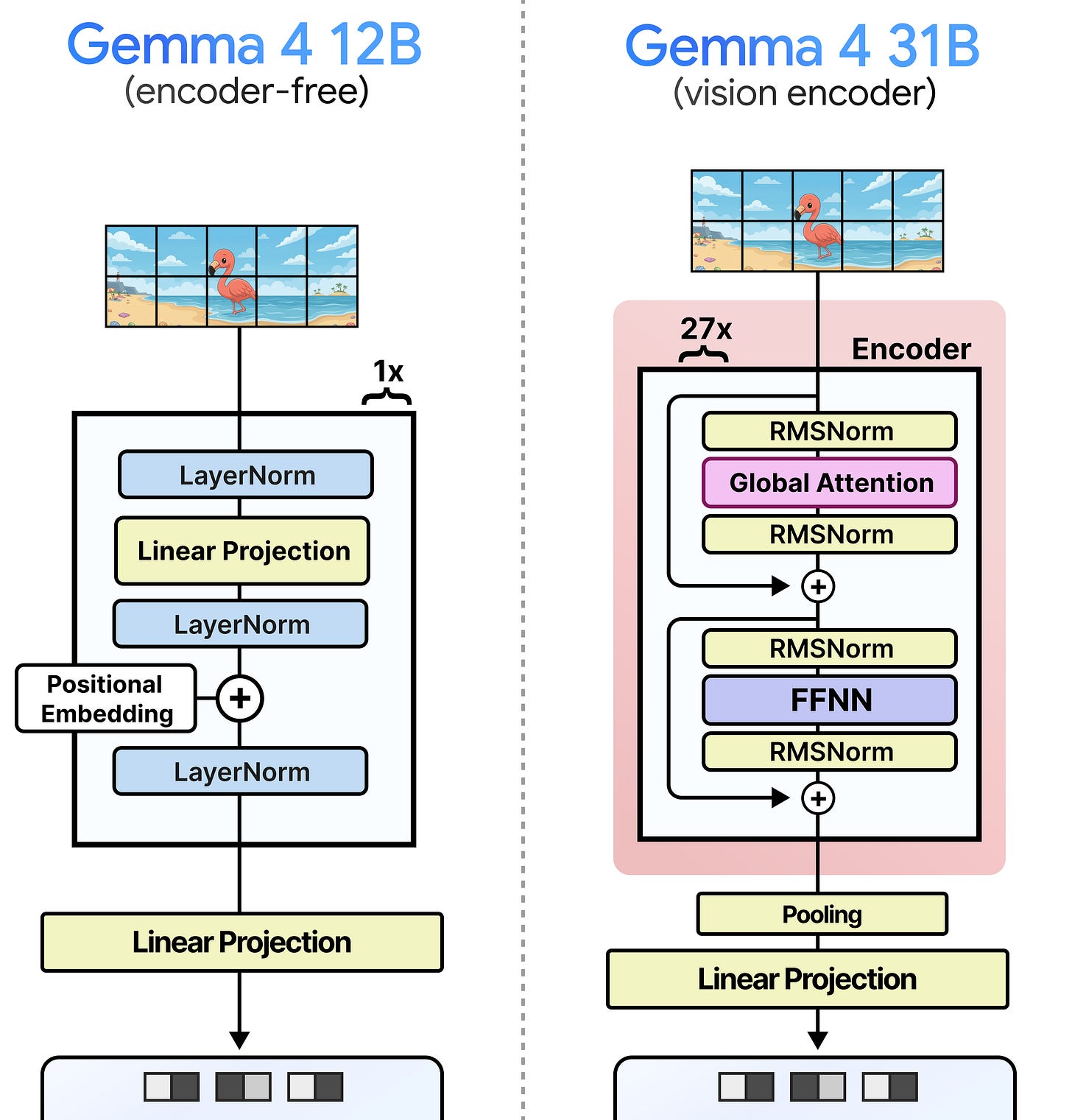
LLM核心架构。仅看LLM本身,Gemma 4 12B的主要架构与31B密集模型相当相似。它使用相同的解码器结构,将局部注意力与全局注意力交错排列,并确保全局注意力总是在最后。
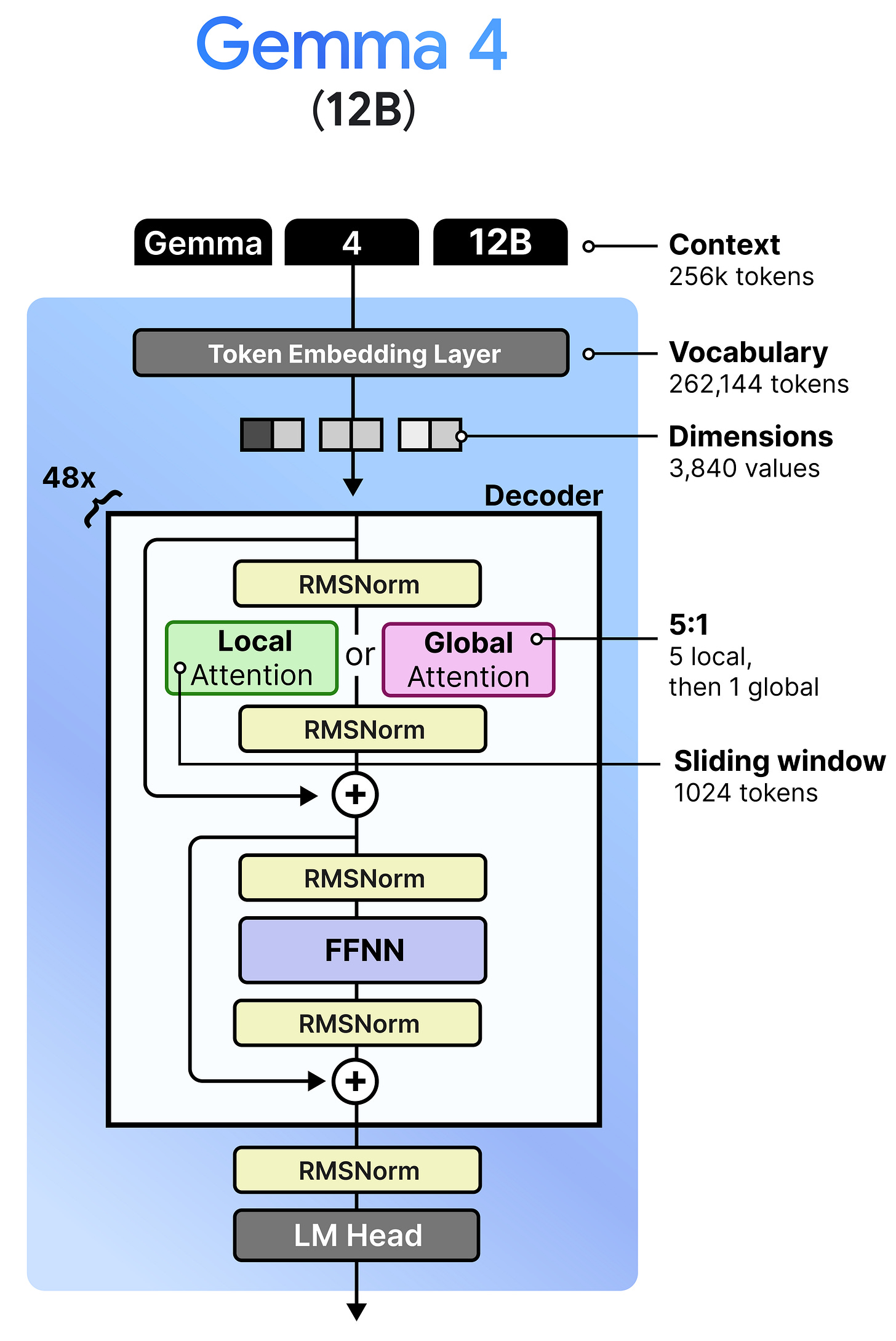
模型定位。该模型很好地定位在现有的E4B和26B A4B模型之间,适合拥有12GB到16GB VRAM的硬件配置。除了尺寸,其主要特点是移除了那些相当庞大的编码器。
替换视觉编码器
轻量级嵌入模块。Gemma 4 12B用一个轻量级的嵌入模块(embedding module)取代了整个视觉编码器。该嵌入模块不再运行15或27个Transformer层来提取和处理视觉特征,而是只包含一个单层来创建嵌入。
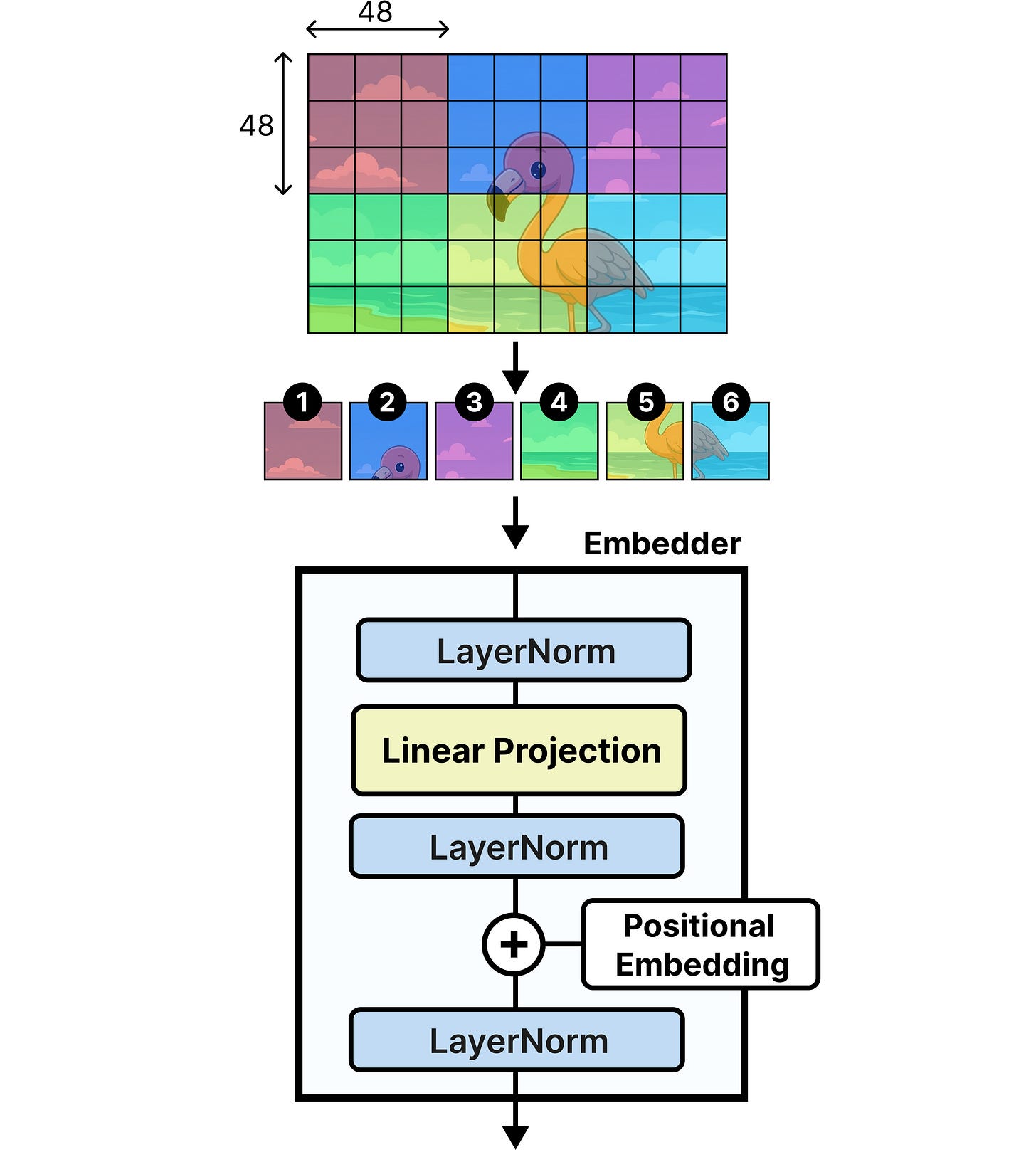
图块处理。模型直接使用48x48的图块,而不是16x16的图块。虽然简化架构是一个不错的副作用,但视觉编码器本可以创建语义丰富的嵌入,而嵌入器则不然。因此,将16x16的图块汇合成48x48的图块不会产生那么大的效果。
位置信息注入。在处理输入图块时,需要添加位置信息,以便LLM了解这些视觉词元在原始图像中的位置。由于嵌入器是无注意力机制的,因此不能像视觉编码器那样使用2D位置RoPE(Rotary Position Embedding)。同样,使用LLM自身的位置编码也不起作用,因为它将其输入视为一维序列。取而代之的方法是,在视觉词元嵌入进入LLM之前,向其注入空间信息。这个过程相当直接,涉及两个矩阵:
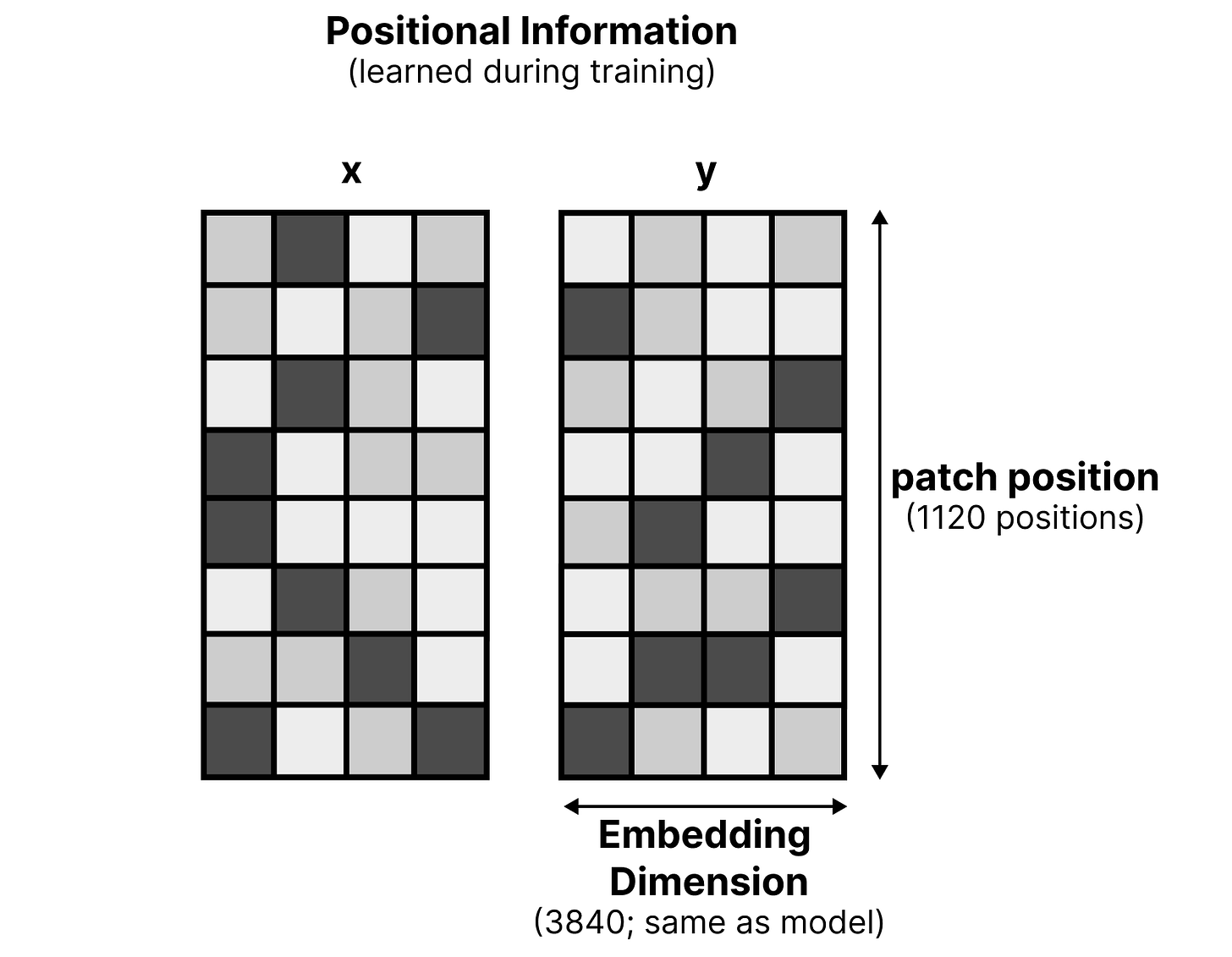
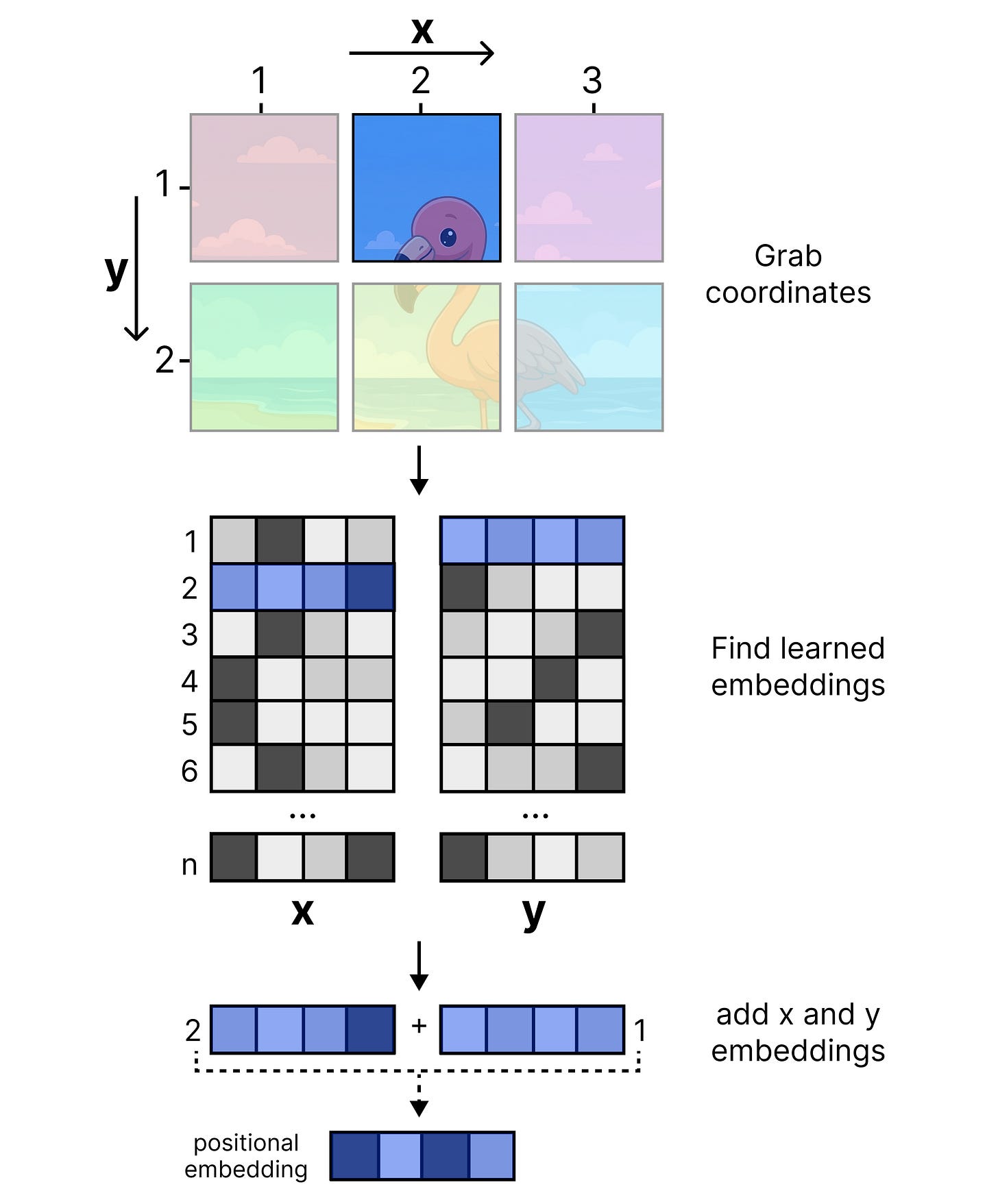
位置编码生成过程。这两个矩阵分别代表图块的x和y坐标。每个矩阵的维度都是1120x3840,其中1120代表图块位置(输入图像的最大图块数),3840与模型的输入维度相同。与带有视觉编码器的Gemma 4模型类似,用户可以选择70、140、280、560或1120个词元(也称为“图块”)的预算大小,这代表了分割图像的最大图块数。对于每个图块,根据其位置添加位置嵌入。例如,一个位于x=2, y=1的图块,会从x和y矩阵中分别选取对应的嵌入,然后将这两个嵌入相加,得到最终的位置嵌入,并加到由嵌入器生成的每个视觉词元嵌入上。
最终处理。在添加位置嵌入后,会有一个最终的LayerNorm层以确保稳定性,然后嵌入被投影到Gemma 4 12B期望的维度。
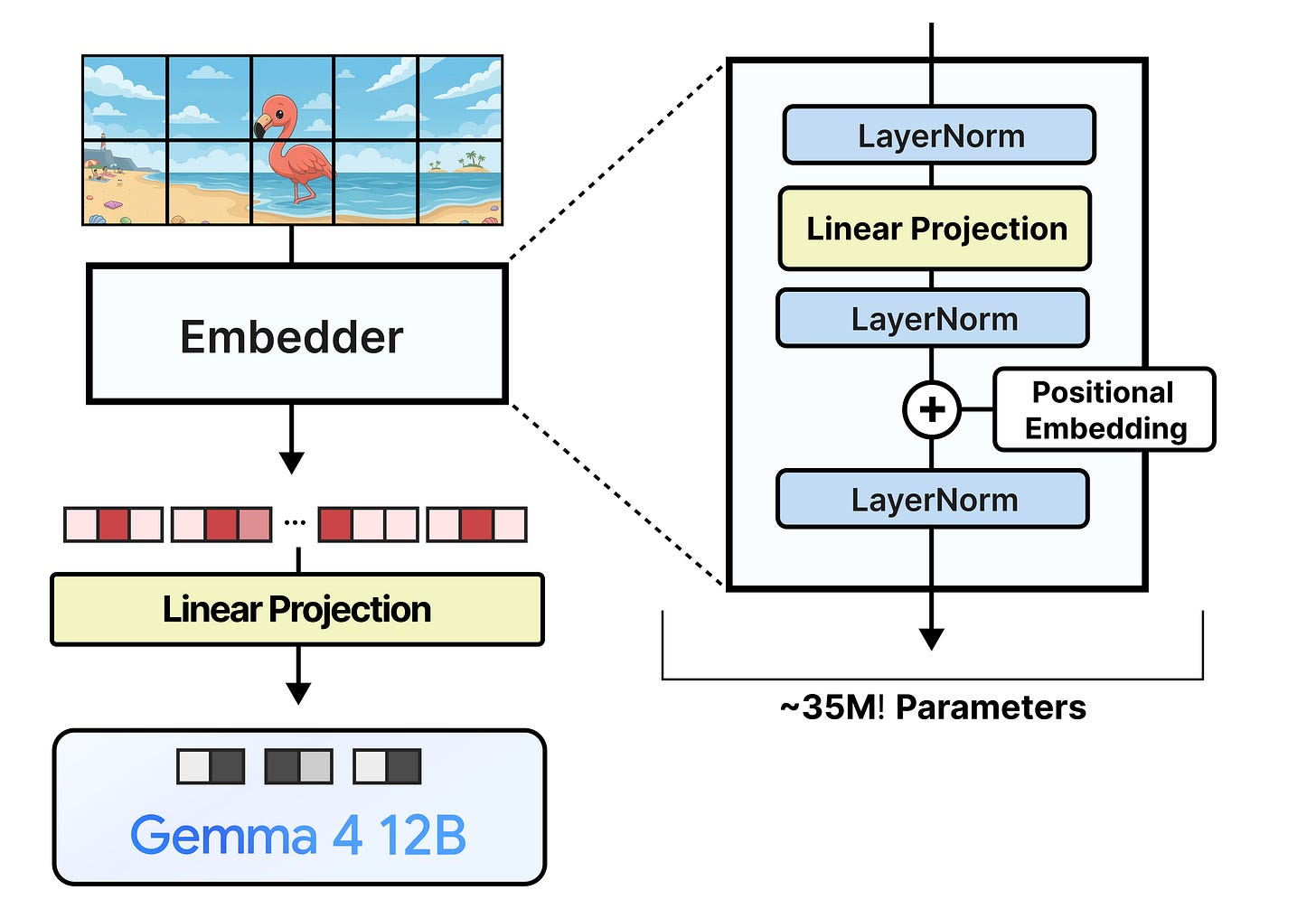
参数量分析。与拥有5.5亿参数视觉编码器的大模型相比,这个嵌入器只有大约3500万参数。这并非没有代价,因为LLM现在必须接管视觉编码器最初所做的处理和理解工作,这需要通过训练来学习。这3500万参数主要来自于将图像图块投影到LLM的维度。每个48x48x3(=6912)像素的图块需要被投影到Gemma 4 12B的维度(3,840)。仅这个投影层(6,912 x 3,840 + 3,840)就占用了大约2600万参数。所以,编码器并非缩减到3500万参数的注意力或前馈网络权重,而是因为有大量的像素需要投影。
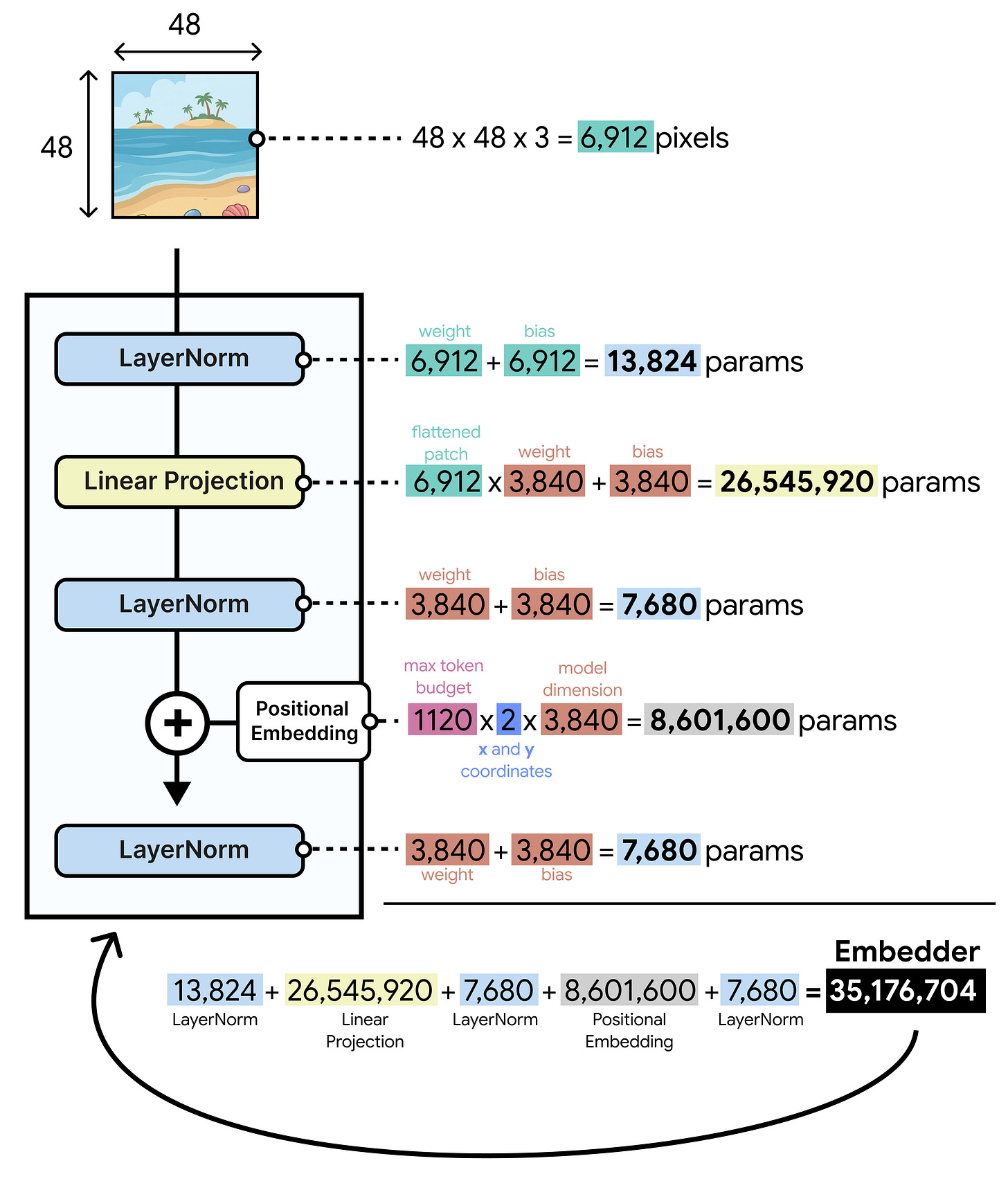
架构对比。与Gemma 4 31B相比,Gemma 4 12B的嵌入器非常小,主要用于添加位置嵌入。除了这一点,嵌入器只有约3500万参数,而前者的视觉编码器约有5.5亿参数。无编码器模型的一个主要好处是,视觉词元能更快地到达LLM,从而使LLM能更早开始处理输入并生成输出。
替换音频编码器
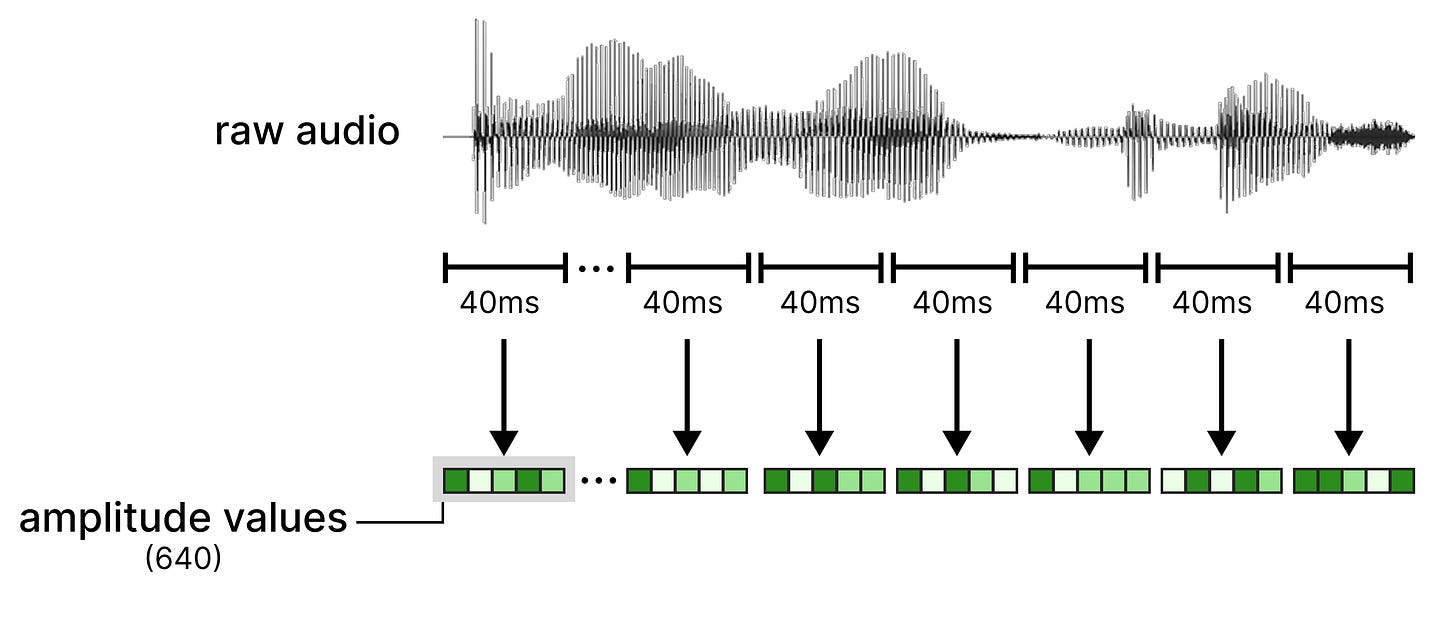
简化处理流程。替换音频编码器的方法与视觉编码器类似,但更为简单。它不再像编码器那样创建经过处理的特征,而是直接使用原始音频输入,就像嵌入器使用原始像素一样。对于音频来说,这有一个主要优势,即不需要额外的位置嵌入。原因是音频本身已经是一个二维序列(原文如此,通常理解为一维时序信号),因此可以像处理文本序列一样进行处理。
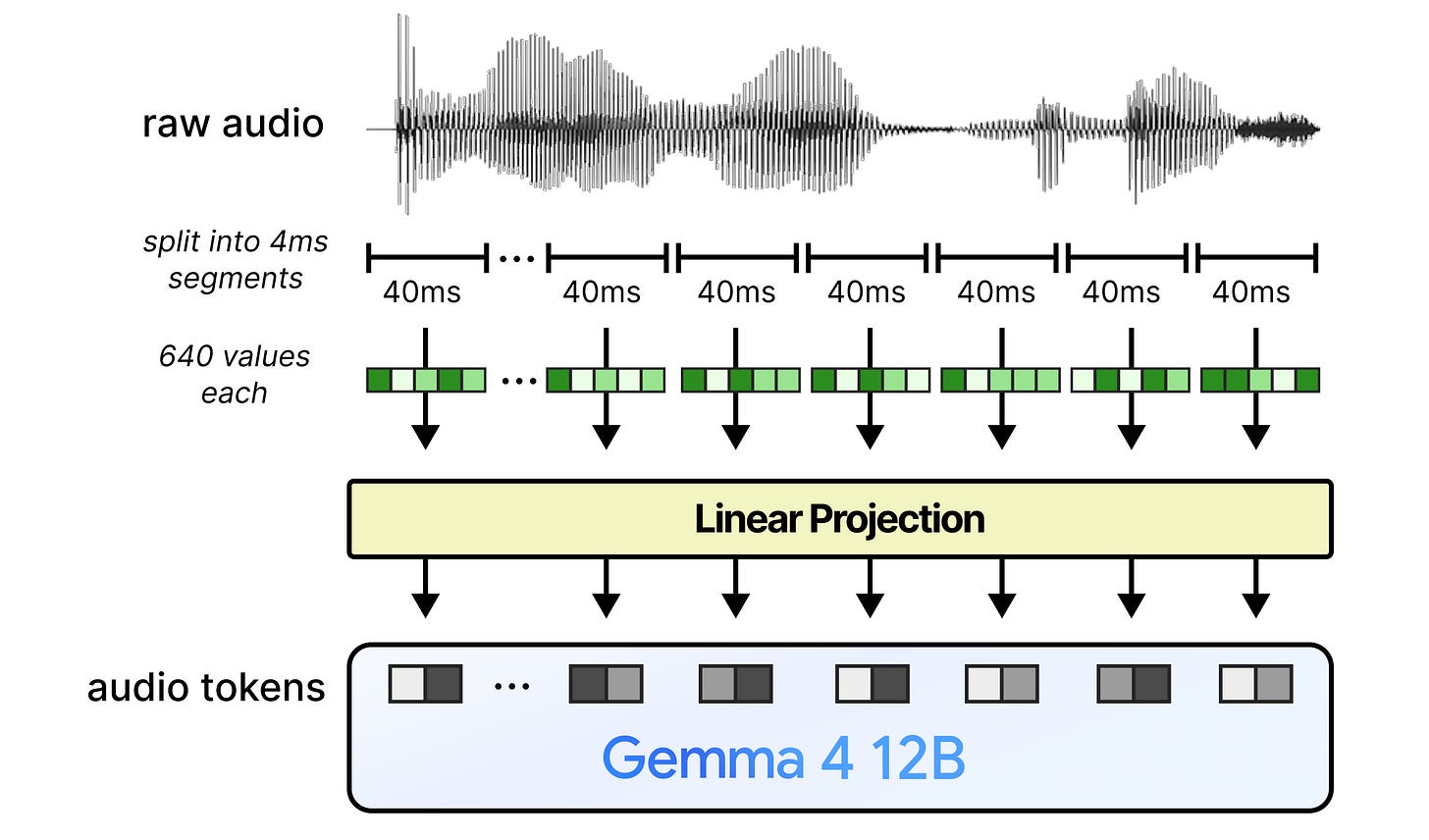
具体步骤。首先,将音频输入分割成40毫秒的序列。音频序列以每秒16,000个快照(16 kHz)的频率录制,每个序列包含640个值。每个值代表声波的高低。这640个值共同构成了原始振幅样本,代表了该序列的原始特征。
投影到LLM维度。然后,这些原始特征被送入一个线性投影层,使其具有与Gemma 4 12B期望的维度相同的维度。
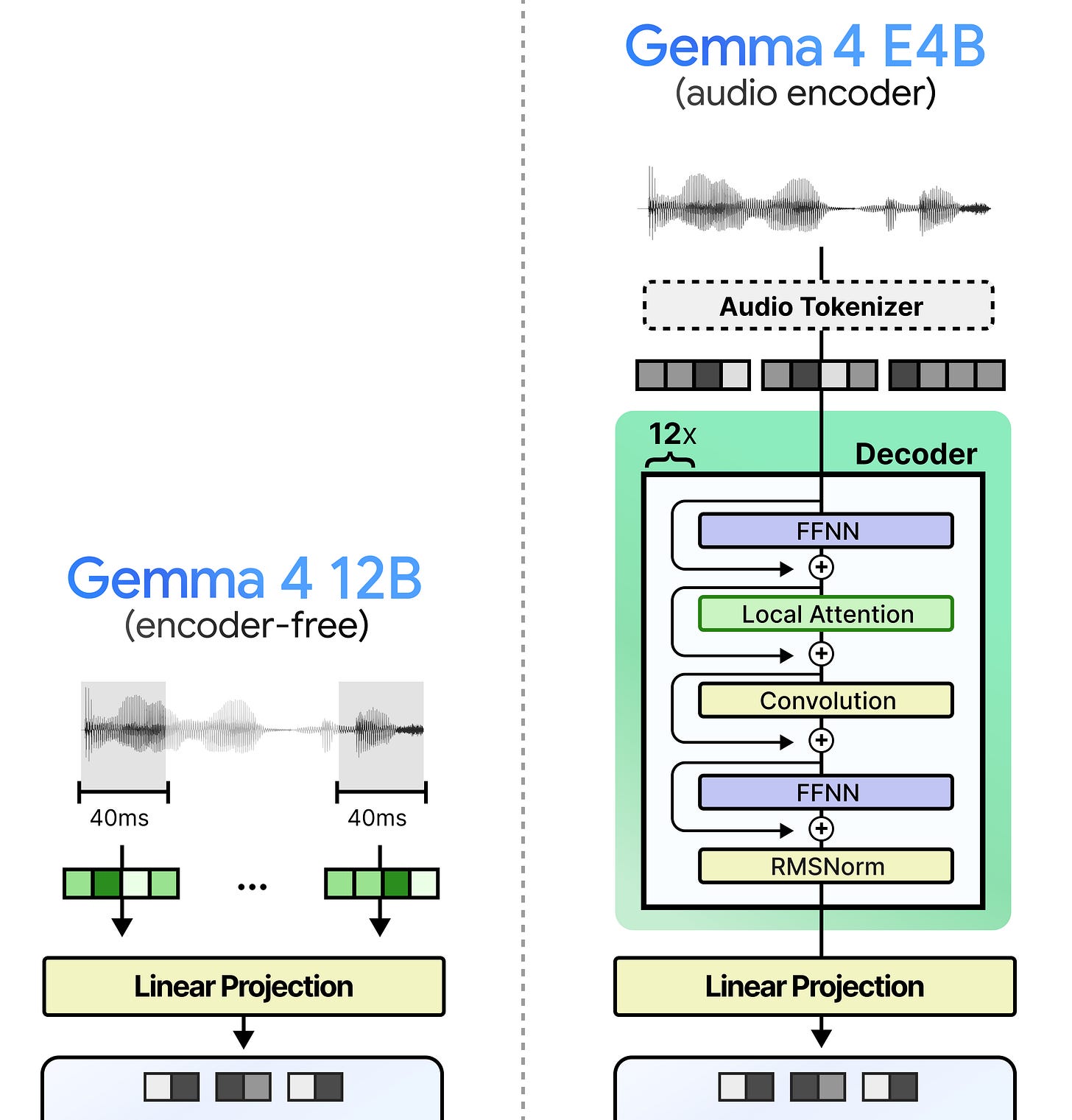
架构对比。这就是全部过程。实际上,所需要做的就是移除编码器,并直接将原始特征投影成与文本词元相同的格式。与需要对音频输入进行分词并通过堆叠的解码器(编码器)进行处理的Gemma 4 E4B相比,Gemma 4 12B仅进行分割和投影,过程极为简化。
Gemma 4 12B 不仅仅是一个填补E4B和26B A4B之间空白的模型,它采用了不同的、有趣的实现方式。
A4 实验环境与结果
本文是一篇技术解读博客,而非正式的学术论文,因此未提供标准的实验设置和量化评估结果(如基准测试得分)。但文章中提供了一些关键的模型参数和硬件考量。
模型架构关键参数:
* Gemma 4 12B:
* LLM架构:与31B密集模型相似,交错使用局部和全局注意力。
* 视觉处理:使用轻量级嵌入模块,约3500万参数。
* 图块大小:48x48像素。
* 位置编码:通过两个1120x3840的矩阵注入x/y坐标信息。
* 投影维度:从6912(48x48x3)投影到3840。
* 音频处理: * 采样率:16 kHz。 * 序列长度:40毫秒,包含640个原始振幅样本。 * 处理方式:直接进行线性投影。
- 其他Gemma 4模型(对比):
- 视觉编码器: E2B/E4B模型为1.5亿参数;26B A4B/31B模型为5.5亿参数。
- 音频编码器: E2B/E4B模型为3.05亿参数。
硬件配置:
- VRAM: Gemma 4 12B 模型适合拥有12GB到16GB VRAM的硬件设置。
实验结论:
文章的结论是定性的,主要强调无编码器架构的优势:
* 低延迟:视觉和音频词元能更快地到达LLM,从而使LLM能更早地开始处理输入并生成输出。
* 架构简化:移除了庞大且复杂的专用编码器,降低了模型的复杂性和总参数量。
A5 结论
作者总结道,Gemma 4 12B模型不仅因其新颖和高性能的设计而令人兴奋,也体现了DeepMind在探索新颖架构方面的研究方向。通过移除专用的视觉和音频编码器,Gemma 4 12B实现了一种更统一、更高效的多模态处理方式,该模型不仅填补了Gemma系列模型尺寸的空白,更在架构上进行了有趣的创新。作者对参与反馈的同事和热情的读者表示感谢,并表示未来将继续创作更多类似的可视化指南。
A7 补充细节
在文章的讨论区,有读者提出了一个技术问题,为模型的细节提供了进一步的思考:
问题: 读者 Eteimorde Youdiowei 提问,既然2D-RoPE(二维旋转位置编码)被移除了,模型是如何学习图像中的相对位置信息的?之前的Gemma 4视觉模型同时使用了2D-RoPE和X/Y图块嵌入表。移除2D-RoPE是否会影响12B模型的视觉能力?
分析: 这个问题指出了Gemma 4 12B视觉处理模块的一个关键变化。在传统的视觉Transformer(如ViT)和之前的Gemma模型中,2D-RoPE在注意力层内部动态地将位置信息编码到查询(query)和键(key)中,帮助模型理解图块之间的相对空间关系。Gemma 4 12B则采用了一种更直接的方式:在图块嵌入进入LLM之前,就将绝对的X和Y位置嵌入(从查找表中获取)直接“添加”到图块的特征表示中。这意味着位置信息被静态地、一次性地注入。模型的能力将依赖于LLM在训练过程中学会如何解释这些被修改过的、包含了位置信号的嵌入,并通过其自身的注意力机制来重建空间关系。这个设计选择的权衡(简化与潜在的性能影响)是该模型架构的一个核心特点。