Gemma 4 12B: The Developer Guide
Gemma 4 12B: The Developer Guide
发表时间: 2026-06 · Blog post by Google Developers (developers.googleblog.com)
文章标题:Gemma 4 12B:开发者指南
作者/机构:André Susano Pinto, Andreas Steiner, Karolis Misiunas, Karsten Roth, Michael Tschannen, Omar Sanseviero (均为Google研究工程师/科学家/技术人员)
A1 主要贡献
Gemma 4 12B 是一款密集的、具有统一且无编码器架构的多模态模型。该模型的发布为本地AI(local AI)带来了几个重要的里程碑:
- 多模态无编码器架构:该模型完全绕过了繁重的多阶段视觉和音频编码器,将多模态数据直接送入大型语言模型(LLM)的骨干网络。这种设计显著降低了处理多模态输入时的延迟。
- 首个支持音频输入的中型模型:在Gemma系列中,音频输入功能以往仅限于小型、轻量级的边缘计算架构(如E4B)。Gemma 4 12B是该系列中第一个能够原生处理音频输入的中型模型。
- 对开发者友好的模型尺寸:该模型足够小,可以在配备16GB显存或统一内存的专用GPU笔记本电脑上本地运行。为了最大化本地推理速度,还额外发布了一个专用的多词元预测(multi-token prediction, MTP)模型。
- 全新的MacOS桌面体验:首次发布了可下载的macOS桌面应用程序,使开发者能够直接在消费级设备上体验完全本地化的语音和视觉交互。
A2 方法细节
传统多模态模型的局限性。传统的多模态模型依赖于独立的、冻结的编码器来处理不同模态的输入。例如,Gemma 4系列中的其他模型使用一个1.5亿参数的视觉模型(用于边缘尺寸)或5.5亿参数的视觉模型(用于中型尺寸),以及一个3亿参数的音频编码器(用于Gemma 4 E2B和E4B)。在将多模态输入送入LLM之前,使用多个独立的编码器进行处理,会导致延迟增加和内存占用碎片化。
Gemma 4 12B的统一架构。Gemma 4 12B通过采用单一的、仅解码器(decoder-only)的Transformer架构来解决上述问题。该架构包含了与Gemma 4 31B密集模型(Dense model)相同的先进解码器结构。
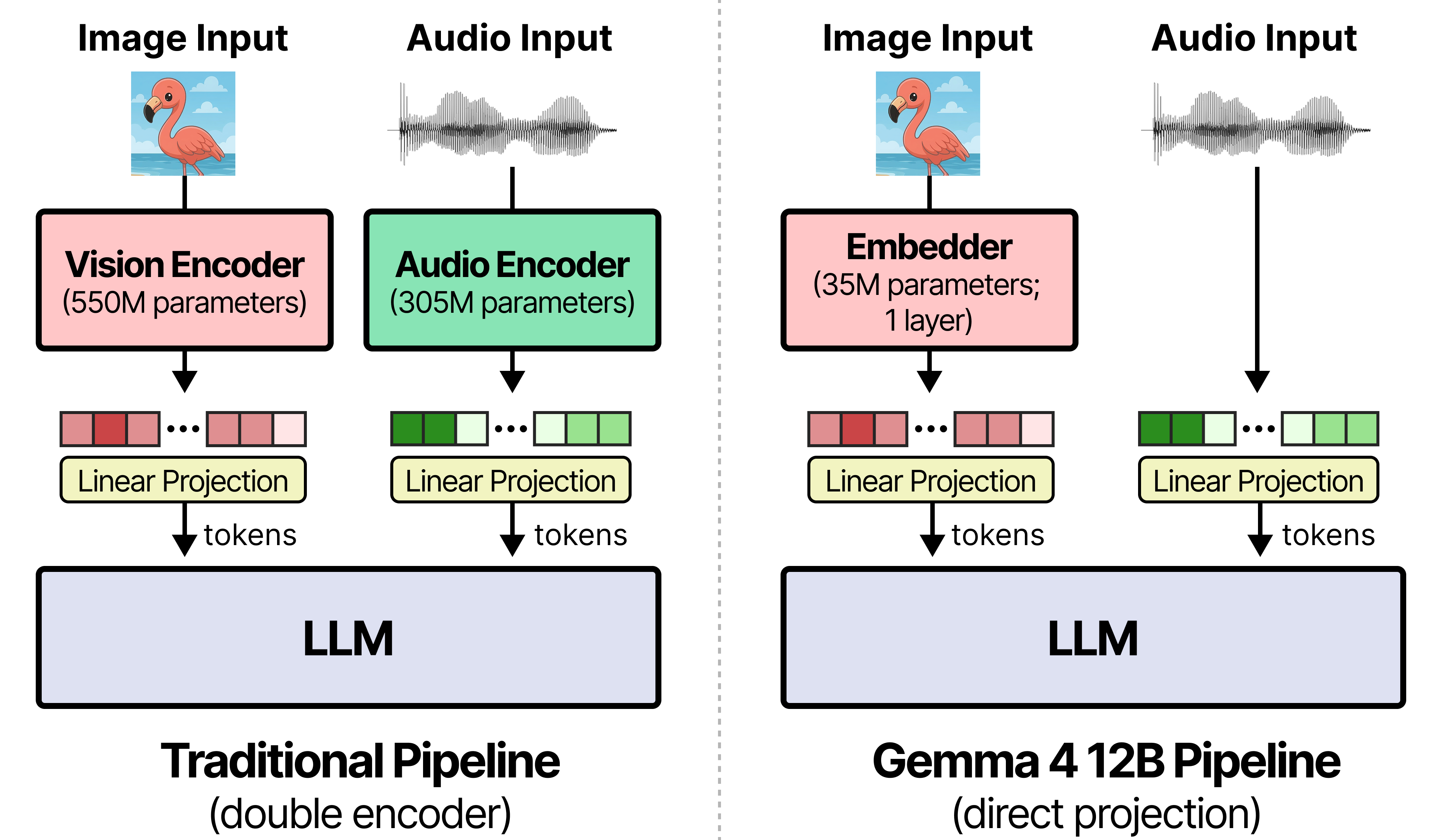
该架构的核心组件包括:
- 视觉嵌入器(35M参数):此组件替代了其他中型Gemma 4模型中的27层视觉Transformer。它将原始的48x48像素图像块通过一次矩阵乘法(matmul)直接投影到LLM的隐藏维度。同时,通过一个分解式坐标查找表(X和Y矩阵)直接将空间位置信息附加到输入中。
- 音频波形投影:该设计消除了独立的音频编码器,跳过了Gemma 4 E2B和E4B模型中使用的12个Conformer层。它将原始的16 kHz音频信号切分成40毫秒的帧(每帧640个浮点数),然后通过线性投影将其映射到LLM的输入空间。
- 统一微调的优势:由于视觉、音频和文本输入共享完全相同的权重,开发者不再需要协同调整(co-tune)多个独立的冻结编码器。下游的适配器微调(如LoRA)或全量微调,可以通过单次传递(single pass)自然地更新整个多模态令牌环路。这一过程可以通过Hugging Face或Unsloth等工具实现。
深入了解无编码器架构。关于这种无编码器架构如何工作的更深入概述,可以查阅文章《https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4-12b》。
A3 实验结果
Gemma 4 12B在多项任务中展现了卓越的性能,其能力涵盖自动语音识别(ASR)、智能体推理(agentic reasoning)、说话人日志(diarization)、视频理解、编码等。以下是展示该模型智能体和多模态能力的具体示例。
示例1:Gemma 4 12B创建一个使用自身的本地图像处理应用
该示例展示了Gemma 4 12B的智能体和多模态理解能力。通过与现有的智能体框架(如OpenCode)结合,并使用llama.cpp和gemma-skills在本地部署,Gemma 4 12B能够编写一个Gradio应用程序来帮助用户处理图像。值得注意的是,这个应用程序本身就是由构建它的同一个Gemma 4 12B模型驱动的。
(原文此处嵌入了一个视频,展示了该过程)
抱歉,您的浏览器不支持播放此视频
示例2:处理5分钟(1 FPS)的带音频视频
研究人员使用Gemma 4 12B分析了https://www.youtube.com/watch?v=wYSncx9zLIU&start=932&end=1245https://www.youtube.com/watch?v=wYSncx9zLIU&start=932&end=1245中从00:15:32到00:20:45的5分钟片段。为此,他们提取了该片段的所有帧(以1 FPS的速率),并结合了视频的音频和以下提示词作为输入。
输入内容:
1. 313帧图像(1 FPS,图像尺寸调整以适应https://ai.google.dev/gemma/docs/capabilities/vision/image?_gl=1*jm0coc*_up*MQ..*_ga*MTI2MzkwODM0NS4xNzgwNDI5Mzg5*_ga_P1DBVKWT6V*czE3ODA0MjkzODkkbzEkZzAkdDE3ODA0MjkzODkkajYwJGwwJGgxOTEyOTEwNzc5#variable_resolution_token_budget为70)。
2. 提示词:"what happens when the man takes a selfie?"(“当那个男人自拍时发生了什么?”)
3. 视频的原始音频以及上述提示词。
模型输出分析:
<blockquote>当那个男人在这些演示视频中“自拍”或被展示手持智能手机放在脸前时,这是一种巧妙的视觉表现方式,用以说明AI模型如何获取现有的媒体——比如一张个人照片或一个视频片段——并对其进行“重构”。在这些特定的片段中,模型获取一张自拍照,并以此为基础生成各种场景(比如一个人在空间站,或在森林中行走)。
从本质上讲,这个男人并非真的在自拍;相反,他是在通过一个视觉隐喻来演示AI的能力,即获取一个特定的输入(一张“自拍”),并基于它生成一个全新的内容世界。这是Gemini Omni模型的“交换”(Swap)和“构建世界”(Build worlds)能力的展示部分,显示了其执行复杂、多模态推理和创造性生成的能力。
</blockquote>A4 补充细节
由LiteRT-LM驱动的设备端和桌面端部署
与Gemma 4 12B一同发布的,还有由LiteRT-LM驱动的强大设备端开发者集成,它将零延迟的本地AI执行能力原生带到标准桌面环境中。
-
原生MacOS应用。移动端的Google AI Edge Gallery应用正式扩展到桌面平台,支持在Apple Silicon GPU上离线、原生运行Gemma 4 12B。该应用内置一个安全的沙箱化Python执行循环,允许用户在聊天气泡内编写、执行代码并绘制科学图表。同时,Mac上的Google AI Edge Eloquent应用也增加了对Gemma 12B的支持,以驱动“语音编辑”(Voice Edit)对话式输入。
(原文此处嵌入了一个视频,展示了应用功能)
抱歉,您的浏览器不支持播放此视频 -
即插即用的本地API服务器 (litert-lm serve)。开发者可以使用新增的
litert-lm servehttps://ai.google.dev/edge/litert-lm/cli将Gemma 4 12B作为本地的、与OpenAI兼容的API服务器运行。这使得它能与标准集成工具(如Continue、Aider、OpenClaw、Hermes或OpenCode)无缝连接。该服务器利用内存中的无状态前缀缓存(stateless prefix caching)来匹配上下文历史记录,从而即时绕过预填充(prefill)延迟。
# 从Hugging Face仓库导入模型
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
# 启动与OpenAI兼容的服务器
litert-lm serve关于此功能的深入探讨,请参阅Google AI Edge Gallery的[这篇博客文章](https://developers.googleblog.com/bringing-gemma-4-12b-to-your-laptop-unlocking-local-agentic-workflows-with-google-ai-edge) 。
A5 实验环境
-
硬件配置:
- GPU:配备16GB显存或统一内存的专用GPU笔记本电脑。
- 平台:支持在Apple Silicon GPU上原生运行。
-
软件配置:
- 模型:Gemma 4 12B的预训练和指令微调检查点。
- 运行/推理工具:LM Studio, Ollama, Google AI Edge Gallery App, Google AI Edge Eloquent, LiteRT-LM CLI, Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM。
- 微调工具:Unsloth。
- 智能体/应用框架:OpenCode, Gradio,
gemma-skills。 - 部署平台:Google Cloud (Gemini Enterprise Agent Platform Model Garden, Cloud Run, GKE)。
-
数据集:
- 本文档为开发者指南,未提及标准基准数据集。
- 示例中使用了Google IO主题演讲的视频片段作为演示数据。
A6 结论
本文档介绍了Gemma 4 12B模型,并鼓励开发者利用其创新的无编码器架构来构建本地化的多模态智能体。为了帮助开发者快速上手,提供了丰富的资源和工具:
- 快速体验:可以通过https://lmstudio.ai/models/gemma-4、https://ollama.com/library/gemma4、https://developers.google.com/edge/gallery、https://ai.google.dev/edge/eloquent应用和https://ai.google.dev/edge/litert-lm/cli等工具进行几下点击即可完成的实验。
- 模型下载:可以直接从https://huggingface.co/collections/google/gemma-4和https://www.kaggle.com/models/google/gemma-4下载预训练和指令微调的模型检查点。
- 学习与集成:提供了https://ai.google.dev/gemma/docs/core和https://ai.google.dev/gemma/docs/capabilities/text/basic供查阅。
- 开发工具支持:可以使用https://huggingface.co/google/gemma-4-12B-it、https://huggingface.co/collections/ggml-org/gemma-4、https://huggingface.co/collections/mlx-community/gemma-4、https://docs.sglang.io/cookbook/autoregressive/Google/Gemma4和https://docs.vllm.ai/projects/recipes/en/latest/Google/Gemma4.html等工具实现本地推理流程,或使用https://unsloth.ai/docs/models/gemma-4高效地进行微调。
- 智能体开发:发布了官方的https://github.com/google-gemma/gemma-skills,这是一个专门为支持使用Gemma模型构建智能体而设计的技能库。
- 灵活部署:可以使用Google Cloud在生产环境中启动端点,通过https://console.cloud.google.com/agent-platform/publishers/google/model-garden/gemma4;publisherModelVersion=gemma-4-12b-it、https://codelabs.developers.google.com/codelabs/cloud-run/cloud-run-gpu-rtx-pro-6000-gemma4-vllm和https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/serve-gemma-gpu-vllm等方式进行部署。
A7 附录
该文档没有附录部分。
引用文献说明
本文为一篇技术博客,未使用传统的数字编号引用格式,而是通过超链接提供了相关背景信息和资源的访问入口。以下是文中提到的主要链接及其内容:
💬 评论讨论
欢迎在这里分享您的想法和见解!